|
My Writing Quality I have always wondered how strong my writing skills are before I turn them in to my teachers. The idea of fully measuring writing quality had really started to interest me. What makes an essay good? Is it how it looks, or how many changes it has? Or is it how fast someone writes it? Taking apart writing patterns, tracking input events, revision ratios, in addition to pause lengths, puts a new idea into the writing process. Consider observing how small things in someone's typing determine how good the writing truly is. Improved technology lets us study all creativity and structure in many new ways. Maybe soon, each student will have tools to give quick feedback. This tool was built as a prototype in order to let people know how well of a writer they truly are. |
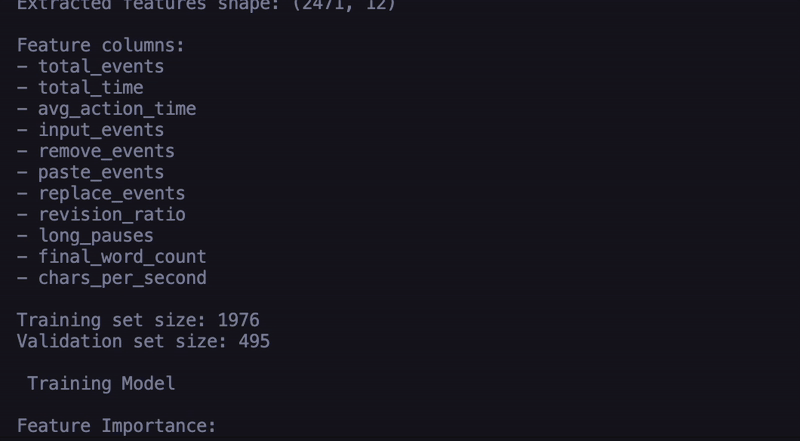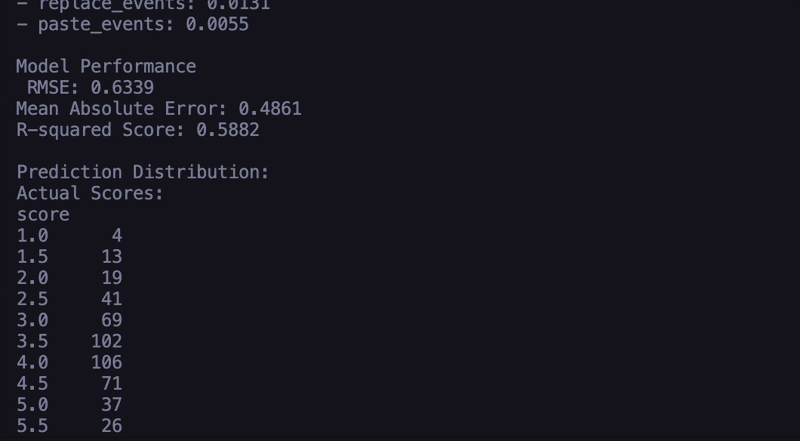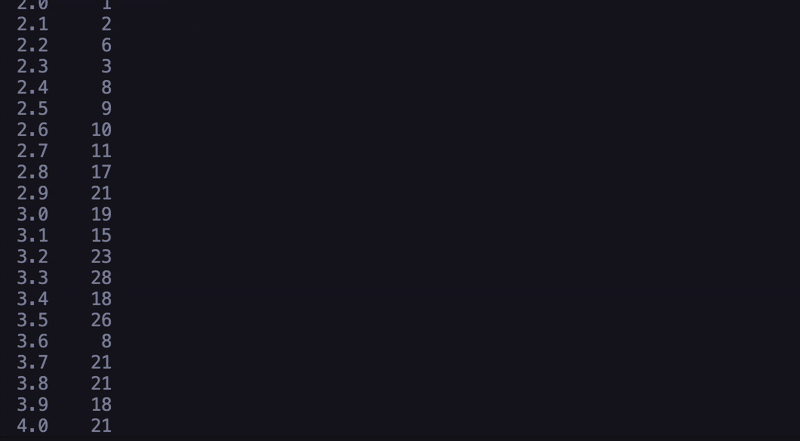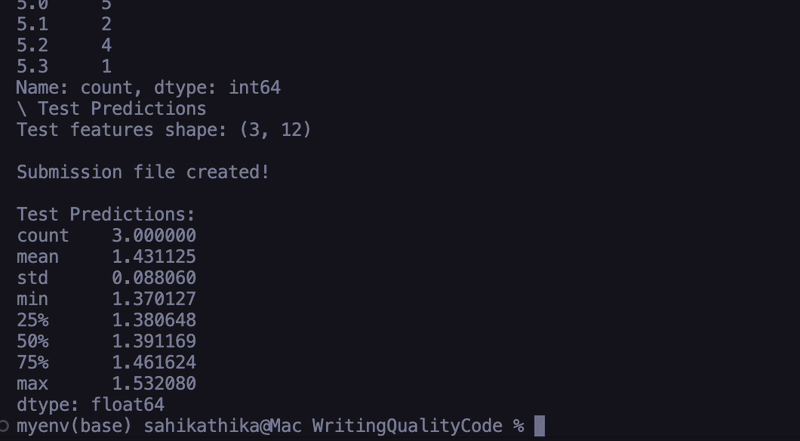
Code Overview:The system starts by loading three key datasets: training logs (containing keystroke data from essays with known scores), training scores (the actual scores for those essays), and test logs (keystroke data from new essays that need scoring). For each essay, the system takes various behavioral features that shows the writing process. These features include the total number of keystrokes, how long the student spent writing, their average time between actions, and different types of writing behaviors, like typing new text, deleting, pasting, or replacing content. It also tracks more complicated metrics like the ratio of revision activities, such as deletions, pastes, and replacements, to total actions, the number of long pauses, the final word count, and the typing speed in characters per second. Once these features are extracted, they're used to train a Random Forest machine learning model. This model learns patterns between these writing behaviors and essay scores from the training data. After training, the model can then predict scores for new essays based solely on how they were written, without ever needing to read the actual content. The system uses multiple decision trees to make its predictions, combining their outputs to generate a final score prediction. This approach suggests that the way a student writes might be just as indicative of essay quality as the content itself. |
| Download the Code and Try It Out! |
|
|
Replicated from Jon Barron. |